 Java技术债务
Java技术债务概述
Kafka是一种分布式的流处理平台,它通过文件存储机制来保证数据的可靠性,高效性和可扩展性。
Kafka的数据存储是基于日志的,它将所有的消息都保存在一个或多个主题(topic)的日志文件中。每个主题都由一个或多个分区(partition)组成,每个分区都是一个有序的、不可修改的消息日志。消息按照它们的写入顺序追加到分区中,并分配一个唯一的偏移量(offset)来标识它们在分区中的位置。
Kafka使用了两个文件来存储消息:消息文件和索引文件。
- 索引文件:以 .index 后缀结尾,存储当前数据文件的索引;
- 数据文件:以 .log 后缀结尾,存储当前索引文件消息的偏移量和物理位置信息
这种分离的存储方式使得Kafka可以高效地执行消息的写入和读取操作。
Kafka的文件存储机制还包括了消息的压缩和清理策略。
Kafka支持Gzip、Snappy和LZ4三种压缩算法,可以将消息在写入到日志文件中之前进行压缩,从而减少磁盘空间的占用。同时,Kafka也支持基于时间或日志大小的消息清理策略,可以根据设定的阈值自动删除过期或过大的消息,以释放存储空间。
此外,Kafka的文件存储机制还支持多副本机制,通过副本机制可以实现高可用性和数据冗余。
每个分区都可以配置多个副本(replica),副本分布在不同的Broker上,可以提高数据的可靠性和可用性。当某个Broker宕机时,其他Broker上的副本可以自动接管它的工作,保证数据不会丢失。
Kafka的文件存储机制还支持批量写入和读取,可以将多个消息一次性写入日志文件中,或一次性读取多个消息,从而提高数据的处理效率。
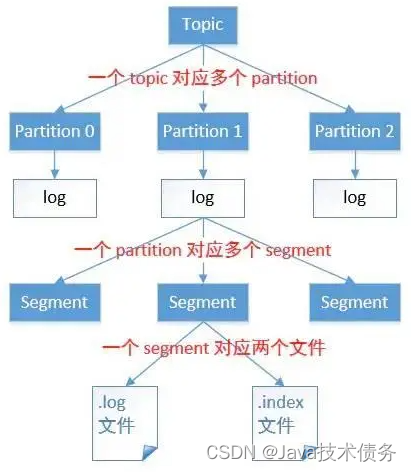
Topic中文件存储方式
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
Partiton中文件存储方式
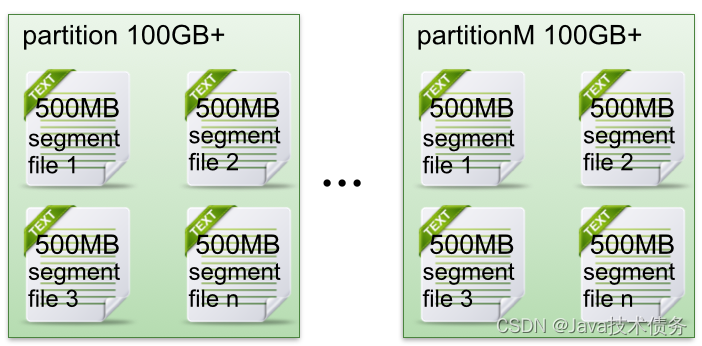
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
segment文件存储结构
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,如下图2所示segment文件列表形象说明了上述2个规则:

以上述图中一对segment file文件为例,说明segment中index<—->data file对应关系物理结构如下:

上述图中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。 其中以索引文件中元数据3497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
从上述图了解到segment data file由许多message组成,下面详细说明message物理结构如下:

| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
在partition中如何通过offset查找message
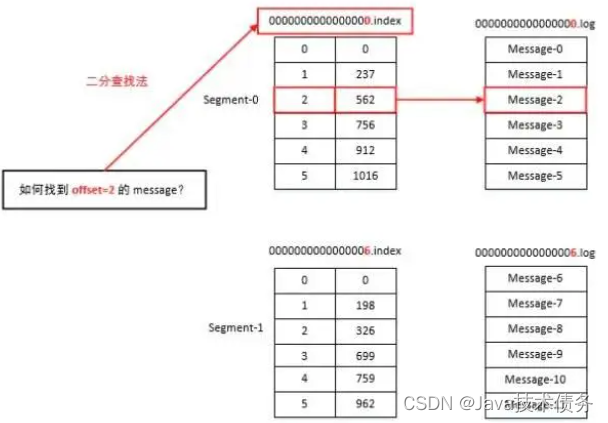
- 首先会根据 offset 值去查找 Segment 中的 index 文件,因为 index 文件是以上个文件的最大 offset 偏移命名的所以可以通过二分法快速定位到索引文件。
- 找到索引文件后,索引文件中保存的是 offset 和对应的消息行在 log 日志中的存储型号,因为 Kafka 采用稀疏矩阵的方式来存储索引信息,并不是每一条索引都存储,所以这里只是查到文件中符合当前 offset 范围的索引。
- 拿到 当前查到的范围索引对应的行号之后再去对应的 log 文件中从 当前 Position 位置开始查找 offset 对应的消息,直到找到该 offset 为止。
从上述图可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
文件存储流程
写message
- 消息从java堆转入page cache(即物理内存)。
- 由异步线程刷盘,消息从page cache刷入磁盘。
读message
- 消息直接从page cache转入socket发送出去。
- 当从page cache没有找到相应数据时,此时会产生磁盘IO,从磁 盘Load消息到page cache,然后直接从socket发出去
Kafka高效文件存储设计特点
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
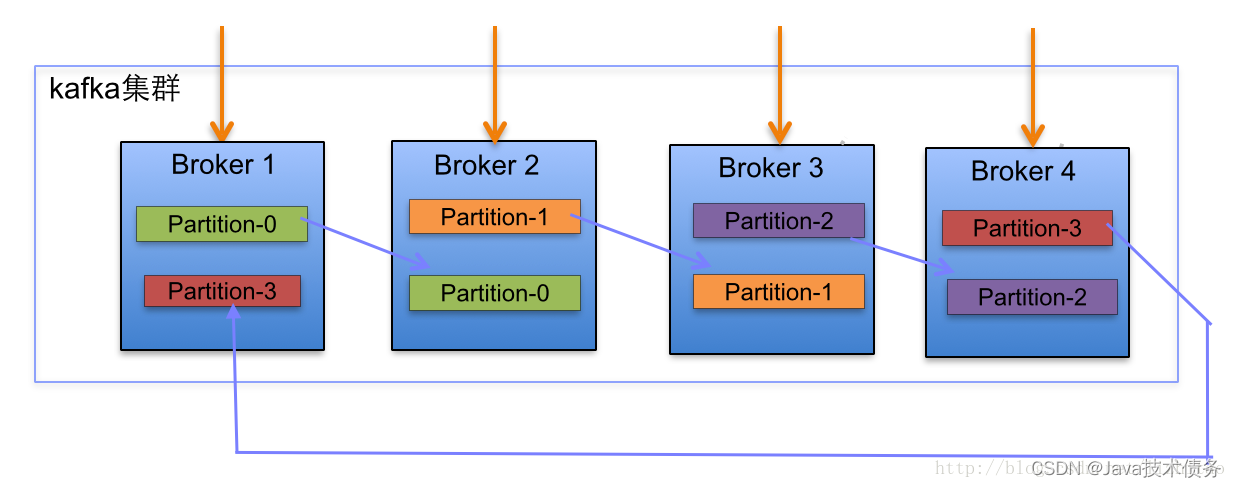
集群partitions和replicas默认分配
下面以一个Kafka集群中4个Broker举例,创建1个topic包含4个Partition,2 Replication;数据Producer流动如图所示:
当集群中新增2节点,Partition增加到6个时分布情况如下:
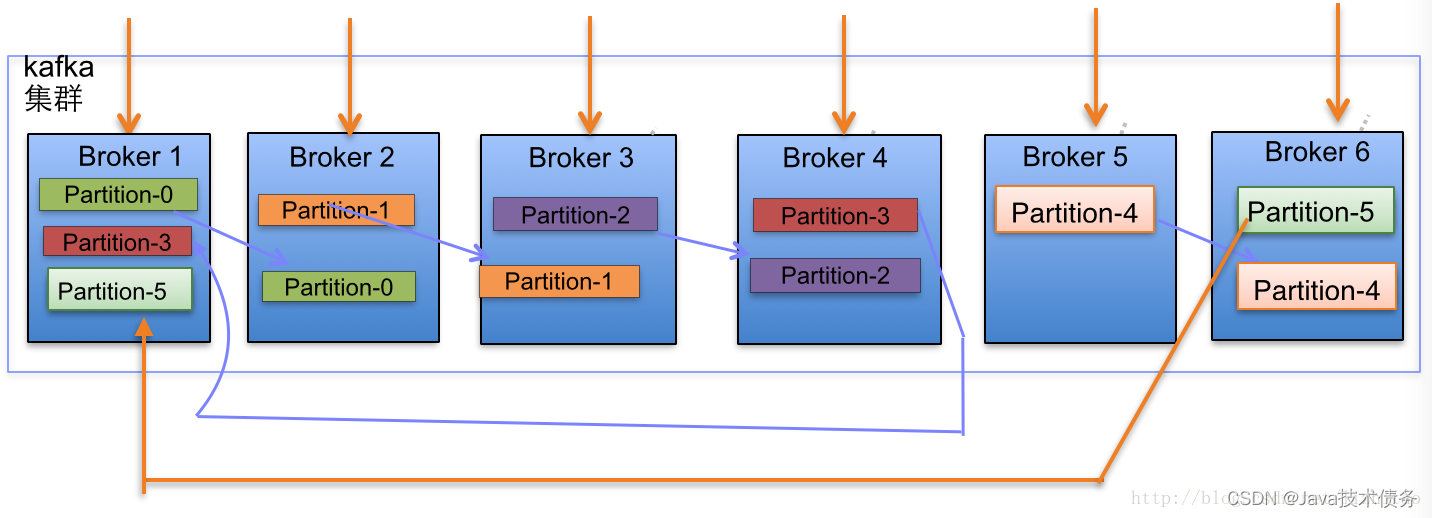
副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.





