Java技术债务
Java技术债务SAMPLE概念
该 SAMPLE 子句允许近似于 SELECT 查询处理。
启用数据采样时,不会对所有数据执行查询,而只对特定部分数据(样本)执行查询。
例如,如果您需要计算所有访问的统计信息,只需对所有访问的1/10分数执行查询,然后将结果乘以10即可。
近似查询处理在以下情况下可能很有用:
- 当你有严格的时间需求(如<100ms),但你不能通过额外的硬件资源来满足他们的成本。
- 当您的原始数据不准确时,所以近似不会明显降低质量。
- 业务需求的目标是近似结果(为了成本效益,或者向高级用户推销确切结果)。
注意: 您只能使用采样中的表 MergeTree 族,并且只有在表创建过程中指定了采样表达式。
SAMPLE功能
- 数据采样是一种确定性机制。 同样的结果
SELECT .. SAMPLE查询始终是相同的。 - 对于不同的表,采样工作始终如一。 对于具有单个采样键的表,具有相同系数的采样总是选择相同的可能数据子集。 例如,用户Id的示例采用来自不同表的所有可能的用户Id的相同子集的行。 这意味着您可以在子查询中使用采样
IN此外,您可以使用JOIN。 - 采样允许从磁盘读取更少的数据。 请注意,您必须正确指定采样键。
SAMPLE语法
| SAMPLE Clause Syntax | 产品描述 |
|---|---|
| SAMPLE k | 这里 k 是从0到1的数字。查询执行于 k 数据的分数。 例如, SAMPLE 0.1 对10%的数据运行查询。 |
| SAMPLE n | 这里 n 是足够大的整数。该查询是在至少一个样本上执行的 n 行(但不超过这个)。 例如, SAMPLE 10000000 在至少10,000,000行上运行查询。 |
| SAMPLE k OFFSET m | 这里 k 和 m 是从0到1的数字。查询在以下示例上执行 k 数据的分数。 用于采样的数据由以下偏移 m 分数。 |
sample K
这里 k 从0到1的数字(支持小数和小数表示法)。 例如, SAMPLE 1/2 或 SAMPLE 0.5.
在一个 SAMPLE k 子句,样品是从 k 数据的分数。
示例如下所示:
SELECT
Title,
count() * 10 AS PageViews
FROM hits_distributed
SAMPLE 0.1
WHERE
CounterID = 34
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000
在此示例中,对0.1(10%)数据的样本执行查询。 聚合函数的值不会自动修正,因此要获得近似结果,值 count() 手动乘以10。
sample N
这里 n 是足够大的整数。 例如, SAMPLE 10000000.
在这种情况下,查询在至少一个样本上执行 n 行(但不超过这个)。 例如, SAMPLE 10000000 在至少10,000,000行上运行查询。
由于数据读取的最小单位是一个颗粒(其大小由 index_granularity 设置),是有意义的设置一个样品,其大小远大于颗粒。
使用时 SAMPLE n 子句,你不知道处理了哪些数据的相对百分比。 所以你不知道聚合函数应该乘以的系数。 使用 _sample_factor 虚拟列得到近似结果。
该 _sample_factor 列包含动态计算的相对系数。 当您执行以下操作时,将自动创建此列 创建
具有指定采样键的表。 的使用示例 _sample_factor 列如下所示。
让我们考虑表 visits,其中包含有关网站访问的统计信息。
SELECT sum(_sample_factor)
FROM visits
SAMPLE 10000000
sample K offset m
这里 k 和 m 是从0到1的数字。
-- 所有数据的十分之一
SAMPLE 1/10
-- 从数据的后半部分取出10%的样本
SAMPLE 1/10 OFFSET 1/2
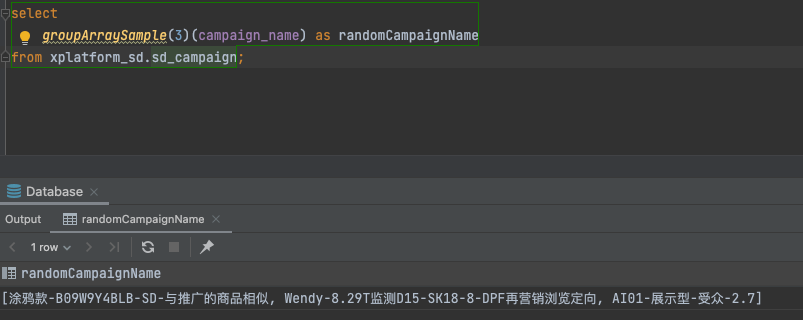
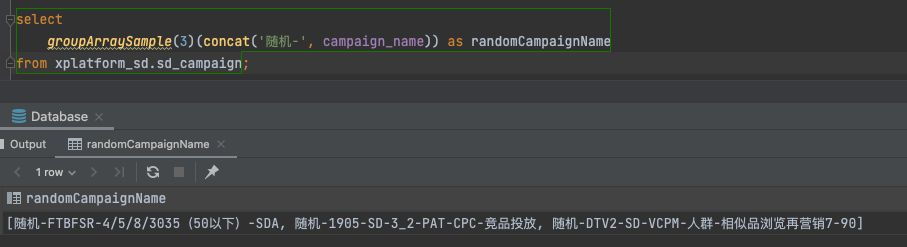
groupArraySample
构建一个参数值的采样数组。 结果数组的大小限制为 max_size 个元素。参数值被随机选择并添加到数组中。
语法
groupArraySample(max_size[, seed])(x)
参数
max_size— 结果数组的最大长度UInt64。seed— 随机数发生器的种子。可选UInt64。默认值:123456。x— 参数 (列名 或者 表达式)。
返回值
- 随机选取参数
x(的值)组成的数组。
类型: Array 示例