 Java技术债务
Java技术债务
概述
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
解释器模式的优缺点
- 优点
- 能够很容易地改变和扩展文法,因为该模式使用类来表示文法规则,你可使用继承来改变或扩展该文法。
- 比较容易实现文法,因为定义抽象语法树中各个节点地类的实现大体类似,这些类都易于直接编写。
- 缺点
- 解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护。
- 易引起类膨胀。
- 可利用的场景较少。
- 解释器模式采用递归调用方法。
解释器模式的结构和实现
模式结构
- AbstrExpression: 抽象表达式
- TerminalExpression: 终结符表达式
- NonterminalExpression: 非终结符表达式
- Context: 环境类:包含解释器之外的一些全局信息
模式实现

我们将创建一个接口 Expression 和实现了 Expression 接口的实体类。定义作为上下文中主要解释器的 TerminalExpression 类。其他的类 OrExpression、AndExpression 用于创建组合式表达式。
InterpreterPatternDemo,我们的演示类使用 Expression 类创建规则和演示表达式的解析。
Expression.java
public interface Expression {
public boolean interpret(String context);
}
TerminalExpression.java
public class TerminalExpression implements Expression {
private String data;
public TerminalExpression(String data){
this.data = data;
}
@Override
public boolean interpret(String context) {
if(context.contains(data)){
return true;
}
return false;
}
}
OrExpression**.java**
public class OrExpression implements Expression {
private Expression expr1 = null;
private Expression expr2 = null;
public OrExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
@Override
public boolean interpret(String context) {
return expr1.interpret(context) || expr2.interpret(context);
}
}
AndExpression.java
public class AndExpression implements Expression {
private Expression expr1 = null;
private Expression expr2 = null;
public AndExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
@Override
public boolean interpret(String context) {
return expr1.interpret(context) && expr2.interpret(context);
}
}
InterpreterPatternDemo.java
public class InterpreterPatternDemo {
//规则:Robert 和 John 是男性
public static Expression getMaleExpression(){
Expression robert = new TerminalExpression("Robert");
Expression john = new TerminalExpression("John");
return new OrExpression(robert, john);
}
//规则:Julie 是一个已婚的女性
public static Expression getMarriedWomanExpression(){
Expression julie = new TerminalExpression("Julie");
Expression married = new TerminalExpression("Married");
return new AndExpression(julie, married);
}
public static void main(String[] args) {
Expression isMale = getMaleExpression();
Expression isMarriedWoman = getMarriedWomanExpression();
System.out.println("John is male? " + isMale.interpret("John"));
System.out.println("Julie is a married women? "
+ isMarriedWoman.interpret("Married Julie"));
}
}
输出结果:
John is male? true
Julie is a married women? true
JDK源码中的使用场景
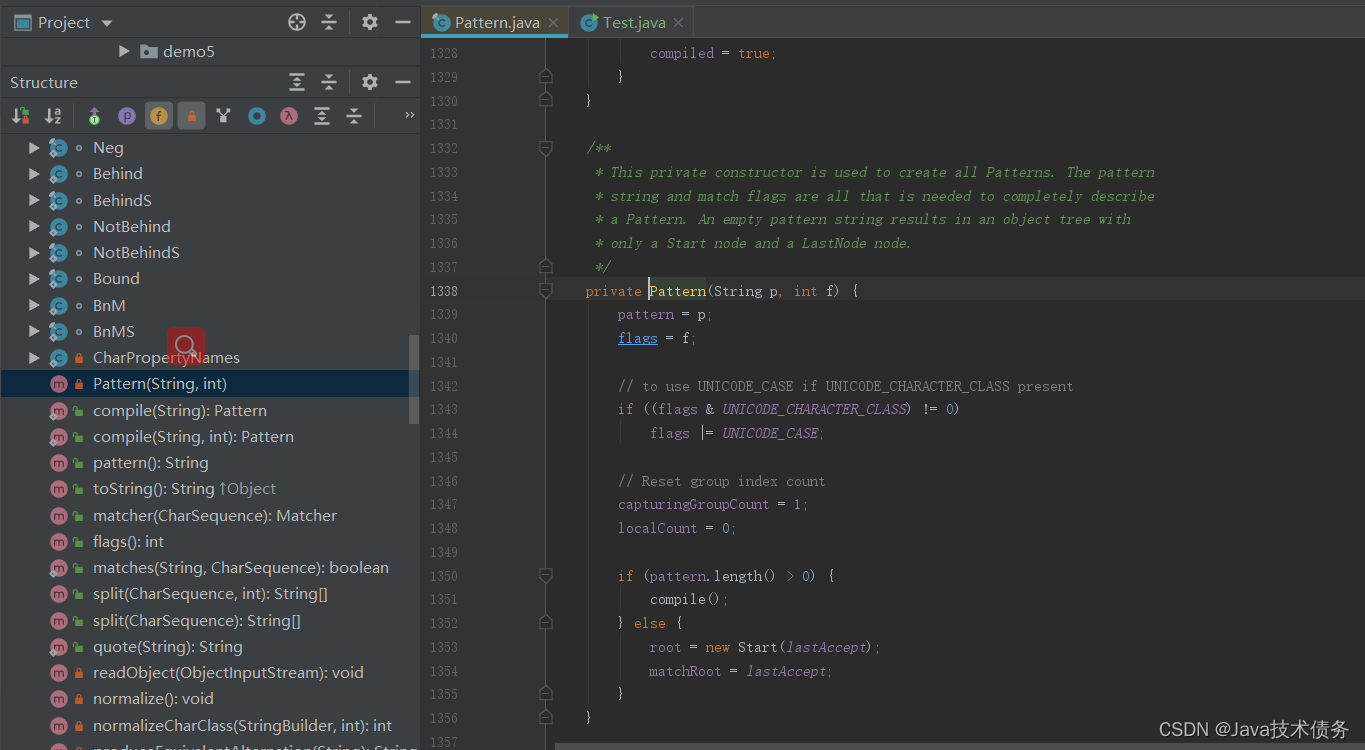
在JDK源码中的Pattern对正则表达式的编译和解析就体现到了解析器模式
private void compile() {
// Handle canonical equivalences
if (has(CANON_EQ) && !has(LITERAL)) {
normalize();
} else {
normalizedPattern = pattern;
}
patternLength = normalizedPattern.length();
// Copy pattern to int array for convenience
// Use double zero to terminate pattern
temp = new int[patternLength + 2];
hasSupplementary = false;
int c, count = 0;
// Convert all chars into code points
for (int x = 0; x < patternLength; x += Character.charCount(c)) {
c = normalizedPattern.codePointAt(x);
if (isSupplementary(c)) {
hasSupplementary = true;
}
temp[count++] = c;
}
patternLength = count; // patternLength now in code points
if (! has(LITERAL))
RemoveQEQuoting();
// Allocate all temporary objects here.
buffer = new int[32];
groupNodes = new GroupHead[10];
namedGroups = null;
if (has(LITERAL)) {
// Literal pattern handling
matchRoot = newSlice(temp, patternLength, hasSupplementary);
matchRoot.next = lastAccept;
} else {
// Start recursive descent parsing
matchRoot = expr(lastAccept);
// Check extra pattern characters
if (patternLength != cursor) {
if (peek() == ')') {
throw error("Unmatched closing ')'");
} else {
throw error("Unexpected internal error");
}
}
}
// Peephole optimization
if (matchRoot instanceof Slice) {
root = BnM.optimize(matchRoot);
if (root == matchRoot) {
root = hasSupplementary ? new StartS(matchRoot) : new Start(matchRoot);
}
} else if (matchRoot instanceof Begin || matchRoot instanceof First) {
root = matchRoot;
} else {
root = hasSupplementary ? new StartS(matchRoot) : new Start(matchRoot);
}
// Release temporary storage
temp = null;
buffer = null;
groupNodes = null;
patternLength = 0;
compiled = true;
}
Map<String, Integer> namedGroups() {
if (namedGroups == null)
namedGroups = new HashMap<>(2);
return namedGroups;
}
private Pattern(String p, int f) {
//保存数据
pattern = p;
flags = f;
// to use UNICODE_CASE if UNICODE_CHARACTER_CLASS present
if ((flags & UNICODE_CHARACTER_CLASS) != 0)
flags |= UNICODE_CASE;
// Reset group index count
capturingGroupCount = 1;
localCount = 0;
if (pattern.length() > 0) {
//调用编译方法
compile();
} else {
root = new Start(lastAccept);
matchRoot = lastAccept;
}
}
总结
优点: 1、可扩展性比较好,灵活。 2、增加了新的解释表达式的方式。 3、易于实现简单文法。
缺点: 1、可利用场景比较少。 2、对于复杂的文法比较难维护。 3、解释器模式会引起类膨胀。 4、解释器模式采用递归调用方法。
使用场景: 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。 2、一些重复出现的问题可以用一种简单的语言来进行表达。 3、一个简单语法需要解释的场景。
注意事项: 可利用场景比较少,JAVA 中如果碰到可以用 expression4J 代替。
 JVM内存泄漏和内存溢出的原因 JVM常用监控工具解释以及使用 Redis 常见面试题(一) ClickHouse之MaterializeMySQL引擎(十) 三种实现分布式锁的实现与区别 线程池的理解以及使用
JVM内存泄漏和内存溢出的原因 JVM常用监控工具解释以及使用 Redis 常见面试题(一) ClickHouse之MaterializeMySQL引擎(十) 三种实现分布式锁的实现与区别 线程池的理解以及使用
最近面试BAT,整理一份面试资料,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。想获取吗?如果你想提升自己,并且想和优秀的人一起进步,感兴趣的朋友,可以在扫码关注下方公众号。资料在公众号里静静的躺着呢。。。
- 喜欢就收藏
- 认同就点赞
- 支持就关注
- 疑问就评论
一键四连,你的offer也四连
概述
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
解释器模式的优缺点
- 优点
- 能够很容易地改变和扩展文法,因为该模式使用类来表示文法规则,你可使用继承来改变或扩展该文法。
- 比较容易实现文法,因为定义抽象语法树中各个节点地类的实现大体类似,这些类都易于直接编写。
- 缺点
- 解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护。
- 易引起类膨胀。
- 可利用的场景较少。
- 解释器模式采用递归调用方法。
解释器模式的结构和实现
模式结构
- AbstrExpression: 抽象表达式
- TerminalExpression: 终结符表达式
- NonterminalExpression: 非终结符表达式
- Context: 环境类:包含解释器之外的一些全局信息
模式实现
我们将创建一个接口 Expression 和实现了 Expression 接口的实体类。定义作为上下文中主要解释器的 TerminalExpression 类。其他的类 OrExpression、AndExpression 用于创建组合式表达式。
InterpreterPatternDemo,我们的演示类使用 Expression 类创建规则和演示表达式的解析。
Expression.java
public interface Expression {
public boolean interpret(String context);
}
TerminalExpression.java
public class TerminalExpression implements Expression {
private String data;
public TerminalExpression(String data){
this.data = data;
}
@Override
public boolean interpret(String context) {
if(context.contains(data)){
return true;
}
return false;
}
}
OrExpression**.java**
public class OrExpression implements Expression {
private Expression expr1 = null;
private Expression expr2 = null;
public OrExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
@Override
public boolean interpret(String context) {
return expr1.interpret(context) || expr2.interpret(context);
}
}
AndExpression.java
public class AndExpression implements Expression {
private Expression expr1 = null;
private Expression expr2 = null;
public AndExpression(Expression expr1, Expression expr2) {
this.expr1 = expr1;
this.expr2 = expr2;
}
@Override
public boolean interpret(String context) {
return expr1.interpret(context) && expr2.interpret(context);
}
}
InterpreterPatternDemo.java
public class InterpreterPatternDemo {
//规则:Robert 和 John 是男性
public static Expression getMaleExpression(){
Expression robert = new TerminalExpression("Robert");
Expression john = new TerminalExpression("John");
return new OrExpression(robert, john);
}
//规则:Julie 是一个已婚的女性
public static Expression getMarriedWomanExpression(){
Expression julie = new TerminalExpression("Julie");
Expression married = new TerminalExpression("Married");
return new AndExpression(julie, married);
}
public static void main(String[] args) {
Expression isMale = getMaleExpression();
Expression isMarriedWoman = getMarriedWomanExpression();
System.out.println("John is male? " + isMale.interpret("John"));
System.out.println("Julie is a married women? "
+ isMarriedWoman.interpret("Married Julie"));
}
}
输出结果:
John is male? true
Julie is a married women? true
JDK源码中的使用场景
在JDK源码中的Pattern对正则表达式的编译和解析就体现到了解析器模式
private void compile() {
// Handle canonical equivalences
if (has(CANON_EQ) && !has(LITERAL)) {
normalize();
} else {
normalizedPattern = pattern;
}
patternLength = normalizedPattern.length();
// Copy pattern to int array for convenience
// Use double zero to terminate pattern
temp = new int[patternLength + 2];
hasSupplementary = false;
int c, count = 0;
// Convert all chars into code points
for (int x = 0; x < patternLength; x += Character.charCount(c)) {
c = normalizedPattern.codePointAt(x);
if (isSupplementary(c)) {
hasSupplementary = true;
}
temp[count++] = c;
}
patternLength = count; // patternLength now in code points
if (! has(LITERAL))
RemoveQEQuoting();
// Allocate all temporary objects here.
buffer = new int[32];
groupNodes = new GroupHead[10];
namedGroups = null;
if (has(LITERAL)) {
// Literal pattern handling
matchRoot = newSlice(temp, patternLength, hasSupplementary);
matchRoot.next = lastAccept;
} else {
// Start recursive descent parsing
matchRoot = expr(lastAccept);
// Check extra pattern characters
if (patternLength != cursor) {
if (peek() == ')') {
throw error("Unmatched closing ')'");
} else {
throw error("Unexpected internal error");
}
}
}
// Peephole optimization
if (matchRoot instanceof Slice) {
root = BnM.optimize(matchRoot);
if (root == matchRoot) {
root = hasSupplementary ? new StartS(matchRoot) : new Start(matchRoot);
}
} else if (matchRoot instanceof Begin || matchRoot instanceof First) {
root = matchRoot;
} else {
root = hasSupplementary ? new StartS(matchRoot) : new Start(matchRoot);
}
// Release temporary storage
temp = null;
buffer = null;
groupNodes = null;
patternLength = 0;
compiled = true;
}
Map<String, Integer> namedGroups() {
if (namedGroups == null)
namedGroups = new HashMap<>(2);
return namedGroups;
}
private Pattern(String p, int f) {
//保存数据
pattern = p;
flags = f;
// to use UNICODE_CASE if UNICODE_CHARACTER_CLASS present
if ((flags & UNICODE_CHARACTER_CLASS) != 0)
flags |= UNICODE_CASE;
// Reset group index count
capturingGroupCount = 1;
localCount = 0;
if (pattern.length() > 0) {
//调用编译方法
compile();
} else {
root = new Start(lastAccept);
matchRoot = lastAccept;
}
}
总结
优点: 1、可扩展性比较好,灵活。 2、增加了新的解释表达式的方式。 3、易于实现简单文法。
缺点: 1、可利用场景比较少。 2、对于复杂的文法比较难维护。 3、解释器模式会引起类膨胀。 4、解释器模式采用递归调用方法。
使用场景: 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。 2、一些重复出现的问题可以用一种简单的语言来进行表达。 3、一个简单语法需要解释的场景。
注意事项: 可利用场景比较少,JAVA 中如果碰到可以用 expression4J 代替。
JVM内存泄漏和内存溢出的原因 JVM常用监控工具解释以及使用 Redis 常见面试题(一) ClickHouse之MaterializeMySQL引擎(十) 三种实现分布式锁的实现与区别 线程池的理解以及使用
最近面试BAT,整理一份面试资料,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。想获取吗?如果你想提升自己,并且想和优秀的人一起进步,感兴趣的朋友,可以在扫码关注下方公众号。资料在公众号里静静的躺着呢。。。
- 喜欢就收藏
- 认同就点赞
- 支持就关注
- 疑问就评论
一键四连,你的offer也四连
- 本文作者:
- 原文链接:
- 版权声明: 本博客所有文章除特别声明外,均采用进行许可。转载请署名作者且注明文章出处。



